






















The Definitive Guide to Master Data Services
Chapter 1: Introduction to Master Data Services
Master Data Services (MDS) is Microsoft’s solution for managing master data. In the past, master data management (MDM) has been a highly problematic area for database administrators. To help you understand better how MDS addresses the inherent challenges of MDM, this guide begins by explaining what MDM encompasses and how it has been handled historically. It then introduces you to MDM solutions other than MDS and explains their shortcomings so that you can fully appreciate the features and functionality of MDS, which is introduced in the latter half of this chapter.
What Is Master Data Management?
Master data management (MDM) is the management of the non-transactional data within an organization. The definition of “master” data varies by organization but can be loosely defined as the nouns that describe all business processes. These nouns might be organization-specific data, like your organization’s list of products or list of employees. Or the nouns might be common reference data provided by an external service provider or government agency, like address information or a Dunn & Bradstreet (D-U-N-S®) number. Although customer and product are the two most commonly managed domains, many businesses find value in managing additional domains, such as wells and fields at big oil companies and recipes at food manufacturers.
In most businesses, customers buy products or services. Because customer relationships are essential, each time a customer buys a product or service, the transaction is recorded. After the transaction is recorded and coded properly, the details of the transaction will never change. MDM is about managing the relationships between these static transactions, rather than the transactions themselves. For example, with a retail chain, each store has a certain group of products that it has in its inventory and a database of registered customers. The list of products available to sell and the list of customer addresses are master data. Sally buying four shirts on Friday is a transaction.
The more often this data is required for a transaction, the greater its importance to your organization. Central management of this data helps identify data discrepancies between multiple transactional systems and helps your organization run more efficiently.
Master data management is composed of the following:
- The business policies (who owns the data, where the data lives, and so forth)
- The processes (how the data is updated)
- The technological tools that facilitate these processes
By definition, all companies must be utilizing some form of MDM, although the term generally refers to the implementation of formalized processes and specifically designed tools.
History of Master Data Management
When companies began using computer applications to manage information, they had to load all pertinent data directly into each application before they could perform tasks and generate results with those applications. Over time, companies adopted more applications and had to enter the same dataset into each of them. As a response to this, developers began to employ the technique of creating master files that stored key, reusable data for use within each application. These initial master files were the first MDM systems.
Once the master data was loaded into each application, new records would be added in the application or to the master list, and the result of which was that the two sets of data were no longer in sync. Early data reconciliation efforts were time consuming and costly. Very few tools existed that could identify differences and manage duplicate records.
Enterprise resource planning (ERP) systems were then created to help combine the data in these systems and to solve the constant need for integration between systems. ERP systems were meant to be single software suites that managed standard business processes within an organization. Each module in an ERP system could leverage the common master data tables required for the associated business process. Many organizations today consider the master data tables within their ERP systems to be the “master” data within their organization.
As more organizations adopted ERP systems, they realized that using these single systems in isolation was an unrealistic solution. They then adopted multiple ERP systems, and their master data problems re-emerged. Specialized systems designed to manage the most problematic domains became major implementations in the larger organizations. Now there is a push in the industry to provide solutions that can solve MDM issues across a multitude of domains.
Overview of Other Master Data Management Solutions
All organizations must deal with their MDM issues. Whether managing domains in Excel spreadsheets or managing them with a specialized solution, a key role of the IT department in any size organization today is to provide processes for managing master data and integrating it across all systems. Various solutions other than MDS are available, but each has weaknesses that are addressed by MDS.
As explained in the following sections, ERP solutions can have several drawbacks as MDM solutions, other specialized solutions can prove to be too specialized, and often MDM solutions typically cater to only the biggest organizations. As you will read later, in MDS, Microsoft hopes to provide an adaptable solution that can cater to organizations of all sizes.
Shortcomings of ERP Systems as MDM Solutions
While ERP systems are a significant consumer of master data, using these systems by themselves to manage master data has major drawbacks. Also, the initial concept vision that a single ERP system would handle all the computing needs of an organization was shortsighted.
- ERP Systems Are Not Specialized or Innovative: While many ERP systems contain modules for most common business processes, a specific industry need or the need for more innovative software leads businesses to implement additional systems. Integration of these new systems with current IT infrastructure and business processes becomes a major implementation cost of any new system.
- ERP Systems Do Not Play Well with Others: When an organization merges with or acquires another organization, it inherits additional ERP systems. Since these systems are highly customized and not initially designed for easy integration, additional processes must be created to ensure that these systems are synchronized across the organization. The complexities of these software systems and the underlying data models make successful integration, or even effective synchronization, extremely difficult for large organizations. When Tyler moved across the country for work, it was impossible for his electronic bank accounts at a nationwide bank to move with him because each of the bank’s regions were on its own system. Imagine, it was easier to move the contents of a house 3,000 miles than to move a set of data and transactions that would fit on a thumb drive.
- ERP Systems Do Not Manage Analytical Dimensions Effectively: The need for complex modeling and analysis of transactional data to determine statistics and trends has led companies to create advanced online analytical processing (OLAP) systems and associated data warehouses to go along with them. These systems have added new, complex data modeling needs that simply were not supported in legacy applications. Hierarchies and other consolidations are not natively managed by ERP systems.
- ERP Systems Are Not Designed to Manage Attributes: Many ERP system vendors realize that users want to store additional attributes in their master tables. To accommodate this, they provide a few custom fields for customers to use as they see fit. These custom fields are overloaded with information without providing any validation of appropriate use.
Specialized Master Data Management Solutions
As you would suspect, the most common domains for management are those domains most troublesome to large organizations. Specialized systems have been created to manage these domains, with many features designed directly for them. These systems were designed to manage a single domain and don’t translate well to other master data problems. The two most common types of specialized solutions for managing master data are customer data integration and product information management.
1. Customer Data Integration: Customer data integration (CDI) solutions are designed to provide a standard view of customers across an organization. Some CDI solutions accomplish this as a single system that centralizes customer data across an enterprise. Other solutions manage the integration of multiple ERP systems and additional systems through a registry approach. These solutions manage customer IDs from multiple systems to ensure synchronization and to provide a consistent view of each customer.
A central feature of CDI solutions is the ability to identify and manage duplicate customer records. Other common features include address correction and standardization and the ability to integrate with service organizations to further enrich business-specific customer knowledge. CDI implementations tend to incorporate most systems within an enterprise and focus on a relatively small subset of attributes.
Companies with customer management problems will certainly benefit from a CDI implementation. Unfortunately, these features do not translate well to managing other domains across the enterprise such as organization or product.
2. Product Information Management: Product information management (PIM) solutions are designed for the product domain. There are fewer PIM solutions than CDI solutions, and PIM solutions tend to focus on specific industries. Most PIM solutions centralize product data management and provide integration to many distribution systems. These solutions tend to be implemented in large retailers and wholesalers that need to manage multiple sales channels for large product catalogs. Management of online catalogs and integration with standardized product channels are some specialized features of PIM solutions.
Again, these systems are highly effective to solve a narrow band of problems. These systems do not translate well to additional domains. Very few providers have solutions in both the CDI and PIM spaces.
Catering to the Titans
Historically, vendors of MDM solutions have catered to the needs of Fortune 500 companies. Until recently, the MDM market was dominated by complex and expensive applications that generate large amounts of consulting dollars for trained implementers. These companies generally have the means and the budget to pay for the consulting time and tools that comprise an MDM solution. These solutions were tied to either a specific domain or a feature set that supported one domain better than others. These solutions are expensive and are built to solve a unique set of issues in large organizations. The size and complexity of these engagements have led many of these projects to end in failure.
The MDM market’s focus on Fortune 500 companies doesn’t mean that small and midsize companies don’t face similar issues with managing their data. Any organization that’s attempting to store critical data in multiple systems or spreadsheets and having trouble determining a true version of its master data needs an MDM solution.
The costs associated with MDM solutions and the high risk of failure in self-deploying such solutions leave a large portion of the small and midsize business market underserved. Out of necessity, many of these businesses are using Excel spreadsheets or internally designed systems to manage master data. These systems typically neglect the need for security, central management, and versioning.
What is Master Data Services?
Microsoft first shipped Master Data Services with SQL Server 2008 R2. That release was largely about Microsoft entering the MDM market and beginning to shape the discussion around MDM. It also provided an opportunity for Microsoft to begin building channels for partners that both implement the solution and create additional applications on top of MDS. In effect, the first release was about getting into the game and the second is about changing the rules. In SQL Server 2012, MDS looks to redefine the MDM market, expanding the types of data stored and easing the barriers to managing it. This section provides a quick overview of the new MDS features in SQL Server 2012 as well as the features carried forward from SQL Server 2008 R2.
What Master Data Services Still Delivers
Master Data Services (MDS) provides several features that facilitate central management of master data while providing greater access to the editors and consumers of this information.
- Domain Agnostic: MDS is not designed for a specific domain. Any data type and virtually any data schema can be supported by the MDS system. Chapter 3 discusses how to map your organization’s systems and determine how MDS might best suit your needs. Chapter 4 shows you how to create your models, entities, and attributes, which are the core MDS objects.
- Hierarchy Management: Excel- and IT-developed applications are notoriously bad at representing hierarchical data. Specialized controls and multiple hierarchy types in MDS provide effective and flexible management of business hierarchies. Chapter 5 shows you how to work with hierarchies and collections.
- Web-Based UI: A web-based user interface (UI) provides access to a large user base without the need for installing software on numerous machines. As intranet access becomes more portable, mobile device access can be integrated into the MDM story.
- Transaction Logging: Even with a robust security model, it is essential to provide an audit trail of changes. MDS provides a filterable transaction log to ensure a manageable history of changes, including the ability to annotate transactions so users can explain why they made changes to the master data.
- Data Validation: Many master data lists require additional validation to ensure certain fields are populated in specific cases. Business Rules can provide users with a proactive monitoring process to ensure data validity before these lists are used in process systems. Chapter 6 shows you how to create business rules.
- Versioning: Many domains require snapshots of different points in time to be maintained. With MDS, each model can be versioned, which allows users to tag specific versions for subscribing systems. Chapter 7 shows you how to create versions of a model.
- Security: The ability to control access at the entity, attribute, and record levels allows IT to empower business stewards to update data in a single centralized tool without risking unauthorized changes. Chapter 9 shows you how to implement security.
The Value Proposition
The MDS system is built to be rapidly deployed for any domain within an organization. Once deployed, all models support additional customization without complex coding or reconfiguration. The intent is to make MDM software more accessible to small and midsize businesses and to aid departments of large companies in creating solutions for themselves. While Master Data Services provides a rich web services platform for system integration and enables you to use web services to create your own custom user interface, you do not need to use web services to take advantage of what MDS has to offer. An MDS implementation can be completed successfully by business users with no programming knowledge.
Chapter 2: Installation and Configuration
The first step in any software application is to deploy the software, and Master Data Services is no exception. This chapter focuses on project size and scope, which should help you determine your needs, including whether you need any external assistance.
Determining the Initial Scope of Your Project
Before installing Master Data Services, it is important to determine your short- and medium-term goals for the application. MDS was designed as a web application to provide a simple deployment model for a wide range of organizations. This is also a good time to make sure you have the necessary information to deploy and configure the application successfully, and to determine whether your project requires external expertise. There are several questions to consider before installing MDS:
- Which domains will I manage in MDS? While this guide addresses how to organize this data, it is important to take an initial assessment of what data must be stored to create a functional MDS solution.
- How many attributes will I need to manage? For each domain that will be managed in MDS, it is valuable to understand the number of attributes that are relevant to the organization. A central benefit of MDS is the ability to modify your model at any time, so a complete list is not essential. A rough estimate of the number of attributes provides one of the best metrics of the scope of the management problem and can provide insight into the owners, editors, and consumers of the records to be managed.
- How many employees will edit the data? To provide an effective long-term solution and to see the largest return on investment (ROI) for any master data management solution, it is imperative to empower the owners of the data to make changes directly within the system. Whether this is accomplished directly in the Master Data Manager web application or in some external entry system that is integrated with MDS, empowering the business owners reduces IT effort and eliminates the communication breakdowns that occur when routing data changes through IT.
- How many employees will consume the data? Ideally, completed implementations should give everyone with a business need in the organization access to the cleanest and most accurate data at all times. In most MDM projects, reaching this ideal state is a work in progress and data consumers should be prioritized based on business need and the costs associated with providing access.
- How many systems do I need to integrate? Depending on the size of the organization, identifying all systems that rely on a specific domain may not be feasible this early in a project. Most small and medium-sized businesses should identify all systems that consume the domain to be mastered and determine the primary owner of each system.
Based on the preliminary data that you discover from answering the preceding questions, you can determine the relative complexity of your MDM project.
The complexity of your project should affect both the scope of the implementation and the amount of ongoing effort required to maintain the MDS project. Small projects should be manageable by novice individuals with sufficient business knowledge and the aid of this guide. These projects should be functional and productive within a week’s worth of effort.
Many small projects revolve around finding a home for “homeless” data within the organization. This data is critical to regular business processes, but not important enough to be managed in any standard process system. Much of this homeless data tends to live in unmanaged Excel spreadsheets. The transition of this homeless data into MDS can provide structure and control over it. If IT personnel were previously responsible for managing changes provided by business users, they can now provide users with access to the appropriate data directly. No formal roles or duties need to be created.
A wide range of projects falls into the intermediate range. These projects can be handled internally but require resources to be fully committed to the implementation effort. Most small and medium-sized business implementations will be intermediate-sized projects. As these projects become more complex, bringing in outside expertise for the implementation should be considered seriously. Making the decision to do so does not diminish the need for internal knowledge and education. Although these consultants will aid in the implementation of the solution initially, internal staff will be needed to maintain the MDM system and processes going forward. Most of these projects can be managed in a single phase, requiring approximately 30 to 200 hours to be successfully implemented. Identification of at least one data steward within the organization is essential for long-term success.
Data steward is a common role found in MDM projects. These individuals tend to be technically savvy while still understanding the nuances of the business domains. A data steward must be a champion of data governance and must help create sustainable data maintenance processes within the organization. Many times, data stewards find themselves acting as referees in how data is maintained, caught between competing business processes and applications. Systems may maintain different rules regarding the quality and timeliness of data that must be managed by the data steward. The ability to find efficient compromises will determine how effective a data steward is for an organization.
Once projects reach a certain level of complexity, they become too large to manage in a single phase. The cost and complexity of these large projects requires engaging external expertise that can provide the guidance and resource necessary to implement enterprise-wide MDM solutions. These large projects may span multiple years and locations and breaking these projects into multiple milestones and ROI checkpoints is advisable. If these projects can be broken down into more manageable intermediate projects, lessons learned from preceding projects can be applied to later implementations.
Chapter 3: Starting an MDS Project
Before you build a model in MDS or any other MDM system, it is essential to have a basic understanding of your data and current processes. In this chapter, we provide deeper insight into what is and is not master data, and we provide some simple labels for your current business systems. Toward the end of the chapter, we discuss some tips and tricks for modeling your data, with the goal of helping you to free your enterprise from many of the data restrictions that have plagued it for so long.
How Do I Know Master Data When I See It?
Over the past year, one of the questions most commonly asked by organizations has been, “Is there a definitive line between master data and other important data in my company?” The truth is, there isn’t one and there shouldn’t be. In most companies, master data management is used only for business-critical domains like product or customer because the implementation of MDM solutions throughout these organizations would be so prohibitively expensive. If an accessible solution with a rapid time to value were available, other important domains could benefit from MDM tools as well.
We’ve already talked about a couple of the key differentiators between master data and transactional data within an enterprise, but they are worth repeating: Data that you wish to store in MDS should not relate to a single event in time because that is transactional data. In MDS, you should store information assigned to a state or that continues to have a state for a specific period. This information is master data.
Business Process Models
Before you build your model in MDS or any other MDM system, it is imperative to understand the flow of data through your enterprise. Where do new accounts, customers, or products originate? What is the process that turns a concept into a product? What is the process to onboard a new customer? How does the data flow from inception to all systems across the organization?
Business process modeling can provide decision makers with the information that they need to prioritize and plan the creation of their MDS implementation. Modeling relevant processes related to the creation and maintenance of domains you are interested in managing is the most logical place to start. Although you could employ skilled business process managers to interview employees and provide detailed designs of their findings, most projects can get by with a do-it-yourself approach.
Your first step should be a quick inventory of any existing documentation of current processes. Much of what you require might already exist. Be sure to review any existing documents with current employees in the modeled roles. It is astounding how quickly reality can diverge from the documentation given a little bit of time. The more manual the processes, the more easily these processes can be changed or abandoned.
When you conduct the interviews required to create a business process model yourself, you should complete the following two steps in sequence. Each step provides insight into the investigated domain. Make sure to record the actors, activity, and length of time required for each business process.
- Determine how new data members are created in the organization. Make sure to investigate any alternative methods that may lead to the creation of a new member. Lead the interview with questions like “How does this system interact with other systems?” or “Are there any emergency processes?” These can lead to important discoveries. As you begin to integrate systems across organizations, it may be pertinent to ask about any automated systems that may generate new members.
- For each of the methods discovered in the previous step, drill into any workflow or process to enrich the data member before you consider it complete and ready for use in any systems within the scope of the project. Each system that depends on this information may have different requirements, so it is best to address each system’s needs. This step is also the best time to identify the primary owner for each business process or system. Primary owners will have a vested interest in their processes and will require assurances that most if not all of their current domain needs will be addressed in any business refactoring.
- All the information you collect will result in a diagram or set of diagrams. These diagrams will help you determine the most palatable flow of master data through the organization. You will need to review each system within the scope of the project to decide what type of role it will play for each domain’s data. Determining the role played by each system is the next step in determining how MDS fits into your organization.
System Roles
Systems can be categorized into three different roles. As different domains have significantly different origination points, it is common for the same system to perform separate roles for different domains within a company.
System of Entry
A system of entry (SOE) is a system where data is first entered into a business. These systems typically include all the users who can create new data. Generally, these are the systems that are used daily by the owners of investigated data. Many systems of entry require that rules be enforced before data can fully be entered. Oftentimes these rules force much of the accumulated information about the member record to be managed outside of the system.
Think of a new product being created. Often, the inception of a new product is scribbled on a napkin or sketched on a whiteboard. Many of the details of the product will be discussed and decided via e-mail format. It is important to capture and manage this process because creating a workflow and roles around product creation can provide many benefits like online collaboration and a tracked history of the creative process. The lack of resources to manage this process often impedes the implementation of a new product.
System of Record
A system of record (SOR) is any system within the organization that is considered the source for other systems. Typically, the enterprise resource planning (ERP) system is the system of record within an organization, but oftentimes many other systems can be considered sources for downstream systems. Many data inconsistencies are created on multiple SORs within an organization. While MDS strives to be an adequate SOE for organizations, it is imperative that many if not all the SORs are moved onto the MDS platform. This is where much of the value of MDM is derived.
Subscribing System
As your MDS implementation matures, the most common type of system should be a subscribing system. Subscribing systems are those systems that consume data from another system with no direct user changes to the managed domain. Some larger companies use an intermediate store to pass data to multiple systems. If direct changes are not made in any of these systems, all these systems can be considered downstream subscribing systems.
Mapping the Data
The next phase in the project plan is to determine data sizes and types within the MDS system. Analysis of all source systems’ main tables and their columns to determine the best data type for storing that data can provide an initial roadmap for MDS. There are two main questions that must be asked during this phase: What types of internal constraints are placed on this column? Are there any downstream constraints in the organization that require further data cleansing to be performed?
You should start the mapping process by identifying those columns within the source system that you will manage in MDS. For each of these columns, determine a rudimentary data type. In Chapter 4, we discuss the different data types available in MDS, but for now just identify data as date, number, or string.
If you identify a date field, be very careful that this field provides information across multiple systems and is a state of the mapped domain. Oftentimes, date fields are red flags that you have mistaken a system-specific field such as “entry date” for a more important field like “start date” or “discontinued date.” You should be extra wary of any column that requires the storage of a specific date or time. These fields generally signal that the information stored is most likely transactional in nature.
Columns that you identify as numeric should be reviewed as well. Is this column storing a valid state on a record? We have seen many projects in which the designers have been tempted to map in fields such as account balances or sales figures. These numbers are subject to daily change and are best handled as part of a business intelligence (BI) solution. Master Data Services does not support simple math functions or consolidations, to dissuade users from storing inappropriate data. This does not mean all numbers should not be stored. MSRP, safety stock levels, standard terms, and credit limits are all valid information for MDS. When identifying numeric columns, you should log the precision, or number of decimal places, each column will require. While many systems may not limit this on the backend, the actual required precision should be easy to determine for the primary system owner.
When mapping a source system to MDS, it may be advisable to create additional tables to store choices for certain fields. Some of these relationships are easy to see. If there is a foreign key relationship within the source system that displays options for one field to another, you should continue to preserve this relationship. For instance, if a customer has a relationship to an address table that stores addresses available to the customer, this relationship can be modeled in MDS.
Some relationships are not quite as evident. For instance, a source system may only store specific attributes as text fields, yet valid values for those text fields may be constrained by the business process. If those values are better managed in a separate table, and a foreign key relationship between those tables would be advisable, you want to highlight those relationships now. Determine if any of these relationships may be reused. For instance, within many data sources, there will be several fields that map to a choice of either Yes or No. In these cases, you may want to create a single entity to store those valid choices.
Determining What to Do with Duplicate Records
Data quality is a major concern for corporations, and the identification and management of duplicate records is a central task in the effort to ensure data quality. Duplicate records exist within organizations for a variety of reasons. One of the biggest reasons employees duplicate records is that they are unaware that records already exist in a separate system, because the systems are not integrated effectively. These records should be merged wherever possible.
Some companies intentionally duplicate records within systems for a specific purpose, typically to work around limitations within current applications to support necessary business processes. In most cases, these duplicates must remain within the business application to continue to provide the workaround they were designed for. Systems that required duplicate member records should never be considered for Systems of Record. When connecting these subscribing systems to the MDS repository, master data attributes should be updated in all downstream attributes.
Determining Which Attributes to Manage
To determine whether an attribute should be managed in MDS, data stewards must decide on the nature of the attribute. Is this a state of the domain? Is this information useful for multiple systems? All numeric and date fields should be evaluated closely. Tracking information should not be managed if it is specific to an application in the organization. Calculated values or balances should not be managed in an MDS system because these values will change over time. Make sure that attributes that store a product’s age are not managed as such but that you manage the product’s date of creation instead.
Summary
It is important to understand the flow of data within an organization before implementing an MDM system. Any system that does not match the natural flow of data through an organization is doomed to fail. Analysis of business processes can provide insight into the flow of related data through the enterprise. All systems within an organization can be classified as either systems of entry, systems of record, or subscribing systems.
Many systems within the organization will have data-cleansing needs. It is important to determine what remediation will be acceptable if duplicate records are found. If history must be maintained for duplicate members, a mapping between the MDS source and the system should be maintained. In the next chapter, we discuss how to create our models in MDS.
Chapter 4: Creating Your Model
In this chapter, we discuss the creation and customization of MDS models. In MDS, models are the central work surface that will be exposed to the master data editors and consumers once your project goes live. The success of your project will depend mainly on how well you design your model.
We begin with a discussion of modeling concepts. Then we show you how to deploy pre-built models.
MDS Modeling Concepts
Master Data Services is made up of a relatively simple group of concepts. These concepts are encapsulated as data containers and services exposed in MDS. While these concepts are simple to understand by themselves, it is the varied and complex data schemas that these concepts support that provide both the power and complexity of MDS. Before we delve into the implementation of the model objects, let’s review general definitions of these MDS concepts. Each of these concepts is described in more detail later in the chapter.
- Models: Models are the highest level of organization within MDS. Models are nothing but containers of related entities. Only entities within the same model can be related within MDS. Models are the first concept discussed in this chapter.
- Entities: Entities are the base containers for data in MDS. In their simplest form, entities can be thought of as tables in a database. Users control the attributes (columns) that are managed for each entity. If explicit hierarchies are enabled for an entity, the entity becomes far more complex, managing parent members and their consolidations as well as collections, their attributes, and the members associated with those collections. Most of this chapter is devoted to discussing how to create the structures of entities.
- Members: Members are the records that populate all the entities created in MDS. Members can be either leaf or consolidated. Leaf members are the primary members of an entity. If an entity is enabled for explicit hierarchies and collections, then consolidated members can be created, and can have their own attributes.
- Attributes: Attributes describe members. Attributes can be loosely thought of as columns in a table. Entities contain members and their attribute values. Attributes can be free-form or domain-based.
- Domain-based Attributes: Domain-based attributes are attributes in which the available values are restricted to the members stored in a related entity. This is like selecting from a predefined list, but in MDS all lists are entities themselves.
- Hierarchies: Hierarchies are consolidations or groupings of members that aid in reporting and analysis. There are two management types for hierarchies in MDS: explicit and derived. Hierarchies enforce rules for member inclusion to ensure consolidations do not lose or double count values in connected applications. Hierarchies will be discussed in detail in Chapter 5.
- Collections: Collections provide member grouping flexibility that is not supported in hierarchies.
Building a Model
Master Data Services begins as a blank canvas, allowing you to create your data models within the product however you choose. The model structure is created in the System Administration functional area of the Master Data Manager web application, or by using the web services. As you create the structure, you can open the Explorer functional area of the UI to see the results of your work. The Explorer functional area is where users will go daily to manage their master data.
Opening the System Administration area of the Master Data Manager web UI for the first time can be a daunting experience. In the latest release, the System Administration will default to the model creation screen if you have not loaded any models. When you first create an MDS database, only the Metadata model is created. Figure 4-1 below shows this first model if you open in the Model View screen. This is the only system model within Master Data Services and has been marked for deprecation in a future release. While this model can still be accessed from System Administration or Explorer as its own model, all access to the Metadata features from your own models has been eliminated through the UI. Access to these features will need to be completed through the web services for Metadata.
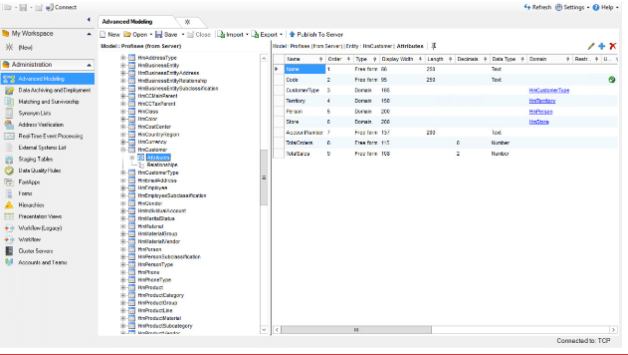
Notice that the menu bar and page title of the System Administration functional area both contain the word “Explorer.” If you go back to the home page, you’ll see that there is an Explorer functional area, where you will manage master data. This is not the same as the System Administration area, where you use the Explorer page to manage your model structure. Most of the time, when we mention Explorer, we are referring to the functional area that you access from the home page of the Master Data Services Web UI.
If you are a new user of MDS, you have two avenues for creating your first useful model within the product. You can load a sample model deployment package into your database and modify the model from there, or you can build your model from scratch.
Starting with a predefined model can be the easiest way to get started with SQL Server MDS. MDS also includes three sample models in the installation. These samples are very basic Customer, Product, and Account models, located in Program Files\Microsoft SQL Server\110\Master Data Services\Samples\Packages. You can look at them to get a better idea of some of the more common features of the application.
While these models provide some data and attributes and support the documentation provided in Microsoft Books Online for SQL Server 2012, they are relatively limited in their functionality and do not provide adequate coverage for the exercises listed in this book. However, these models include sample data, hierarchies, business rules, and versioning, so you can see what the result of all your upcoming work might look like.
Deploying a Model
A model deployment package is an XML file saved with a .pkg extension. It includes the model structure, the business rules (Chapter 6), and version flags (Chapter 7) and Subscription views (Chapter 10). It does not include file attributes (Chapter 4), and user and group permissions (Chapter 9). Model packages can contain the data from a version of the model when created from the ModelDeploy.exe command-line executable. Only the model structure can be created or deployed from the web UI in the SQL Server 2012 version of Master Data Services. The new utility and the limitations on data in the UI were added in response due to the inability to support all model sizes through the web services.
Model deployment in MDS was designed to provide organizations with two very important capabilities related to managing data models in MDS. The first is the capability to develop, test, and deploy a model within three separate implementations of MDS, while limiting the number of objects that need to be re-created in each environment. This enables IT management to roll out changes together and to ensure that the production environment remains operational throughout the process.
The second capability enables organizations to share their model schemas with others. There are several efforts across a host of industries to standardize object models. Previously, most organizations would develop data models in a vacuum, creating schemas that solved their current problem most efficiently. They integrated only those applications owned by the organization and central to the solution. IT departments at all their competitors were doing the same. This led to a wide variety of data models among competitors in the same industry. Some organizations built data models that were flexible, stable, and scalable, but many did not. When consolidation within an industry occurred, acquiring companies discovered similar business processes were hard to integrate due to the vastly different data models that had been developed in isolation.
The following are advantages to employing common data models within an industry:
- Benefit of experience: Civilization wouldn’t get very far if each new generation needed to reinvent the wheel. By leveraging a common data model developed by industry experts, companies can avoid issues that they might otherwise experience personally.
- Standardization: Standards help companies and software providers by limiting the amount of variation that must be managed. Standards allow companies to better manage acquisitions and new integration projects. Software can focus on enhancing business value as opposed to compatibility.
MDS supports these efforts in two ways. By not enforcing its own model, MDS ensures there is one less data model to be managed. Model deployment empowers industry leaders to quickly build master data–centric versions of these industry models, providing efficient deployment across their industry. Any customization that needs be made to these standardized models is still supported in MDS.
About Models
As discussed previously, models are the highest level of organization within Master Data Services. Models are nothing but containers of related entities. Only entities within the same model can be related within MDS. This supports a simplified versioning model where all entities within a model are versioned simultaneously. Although many models revolve around a single domain such as customer or product, this is not a requirement. You can combine major entities into a single model if this makes business sense.
When determining whether to include an entity in a model, there are several factors to consider:
- Do the entities in the model have a relationship to one another? If so, is this relationship master data? Many entities have relationships that are transactional in nature. Only those relationships that change over time and are not discrete instances should be managed in the MDS system.
- Do the entities change on similar schedules? If the two entities have a natural affinity to be versioned at separate times, you may need to manage them in separate models.
- Does an entity only relate to a subset of another entity? If only a subset of the members participates in the relationship between the two entities, ensuring accurate selection may be compromised. Business rules can be used to ensure only the valid members are selected; business rules will be discussed in greater detail in Chapter 6.
About Entities
In MDS, all data that is managed by the system is stored in entities. Entities can be loosely thought of as tables in SQL. The data within entities are called members.
MDS’s entities can also support explicit hierarchies. Once explicit hierarchies have been enabled for an entity, an entity becomes far more than a single table. The entity can then support parent and collection members, as well as hierarchy and collection relationships. Hierarchies and collections are discussed in detail in Chapter 5.
About Members
Members are the individual records stored in Master Data Services. Members are uniquely identified by the required Code attribute. There are two types of members in MDS: leaf members and consolidated members.
Leaf members are the most granular level of records in an entity and usually represent physical objects within your business. For example, in a Product entity, a leaf member might be Men’s Shirt #602. A leaf member in an Employee entity might be John Smith. A leaf member in a Warehouse entity might be Warehouse-98101.
One notable exception to this rule of thumb applies to any entities managed within the Finance domain. When managing entities associated with Finance, leaf members typically represent those low-level identifiers that transactions can be coded to. If transactions are coded with a store, account, employee, and product, you can be assured that the available values for each of these attributes should be stored as leaf member records in the associated entities.
Consolidated members are used only in explicit hierarchies and will be discussed in more detail in Chapter 5.
About Attributes
All entities within Master Data Services can be enriched by the creation of additional attributes. MDS supports a subset of the attributes supported in SQL Server. MDS supports four specific types of free-form attributes for leaf and consolidated entity members: text, DateTime, number, and link. Text and link are essentially string fields, with link providing one-click support for hypertext links. Number supports as many as seven decimals, and DateTime allows you to specify the mask for how the data will be input.
To relate two entities and ensure that values are constrained to specific values, MDS gives users the ability to create domain-based attributes. These attributes limit available values to the list of active members within the related entity.
The last type of attribute available to entities is the file attribute. Within a master data entity, it may be advisable to manage some files associated with each member. For instance, there may be instruction documents, specifications, blueprints, or photos that need to be associated with a Product entity within an organization. However, the file attribute has several limitations that make it less attractive to use for file management than SharePoint. First, to limit the database sizes of MDS, file attributes will not be versioned. Only the last loaded file will be available within the MDS system. The transaction log will display information related to new files that have been loaded, but these will not be reversible.
About Attribute Groups
Master Data Services can contain every attribute associated with an entity in a business. Because of this, some entities can become unwieldy when viewed as a single table in the web UI.
In a large organization, it is common for a major entity to contain over 400 attributes. Very few, if any, system users are interested in viewing all attributes simultaneously. Most users are interested in viewing only specific, related attributes at any one time. MDS provides the ability to group attributes into multiple tabs in the Master Data Manager web application. MDS calls these groupings attribute groups. Any attribute can be added to any attribute group.
Typically attribute groups are created for each role consuming data within an entity. Different functional areas of the organization will be concerned with different groups of attributes for each entity stored in the application. Access to attribute groups can be managed by applying security for different users or groups at the attribute group level. This will be covered in more detail in Chapter 9.
Chapter 5: Working with Hierarchies and Collections
Businesses are not built only on lists; they require more complex structures for data. Dollars, units, and hours must all be calculated to produce consolidated views of a business. For many years, companies have been using business intelligence (BI) applications to better understand their businesses and discover opportunities for both cost savings and revenue growth. At the heart of these applications are the hierarchies that make consolidations possible.
When managing consolidations within a business, it is imperative that all values are accounted for only once. To ensure this, hierarchies in Master Data Services enforce that all leaf members have only one parent. This limits your ability to manage many-to-many relationships within MDS and display these relationships hierarchically.
In this chapter, we review the two primary types of hierarchies supported in MDS.
Ragged vs. Level-Based Hierarchies
When you’re working with hierarchies, it is important to understand some common terms used across applications. Any hierarchy can be either ragged or level-based. Ragged describes hierarchies that support leaf members at multiple levels. A hierarchy is level based if leaf members always exist at the same level, regardless of the number of levels within the hierarchy.
Some business applications do not support ragged hierarchies, so it is important to know the limitations of downstream systems before you create hierarchies in MDS.
Derived Hierarchies
In MDS, derived hierarchies provide the ability to highlight preexisting data relationships within entities and display them hierarchically. Derived hierarchies are based on the pre-existing data relationships within MDS. In SQL Server 2012, derived hierarchies have been expanded to allow more complex relationships to be managed effectively. As the MDS product advances, derived hierarchies will continue to evolve to handle all data relationships, and explicit hierarchies will lose importance. Derived hierarchies are always level-based. This means that every level within the hierarchy corresponds to a specific domain-based attribute within the entity–attribute chain (see Figure 6-1).
Explicit Hierarchies
Explicit hierarchies are multi-level hierarchies with very few restrictions. Explicit hierarchies are managed as name–value pairs, with consolidated members containing other consolidated or leaf members. Explicit hierarchies are created for one entity at a time. Derived hierarchies, in contrast, require multiple entities.
Consolidated members are almost always theoretical items, whereas leaf members represent physical items. Like leaf members, consolidated members can have attributes assigned to them. In the MDS database, a separate table exists to manage consolidated members and their associated attributes. Consolidated members are available only if an entity is enabled for explicit hierarchies. Each consolidated member can be associated with only a single hierarchy no matter how many explicit hierarchies have been created for the entity.
Derived vs. Explicit: Which Hierarchy Is Best?
Derived hierarchies are determined by the structure of the model, and changes to the structure are rare. To illustrate the value of this rigor, consider the following scenario that organizations commonly encounter:
A fictional company devises a regional hierarchy to manage sales. As with most of these hierarchies, this hierarchy begins as a level-based hierarchy, with each level within the hierarchy corresponding to a distinct type of attribute. To store the hierarchy, IT uses the parent-child format from its analysis system.
Over time, this hierarchy is modified by mid-level managers to help them manage their divisions better. Changes are not centrally managed, and new levels are added monthly. John is the manager of the Western region of the company. John has two managers who split duties managing the Southwest division for him: Bill and Margaret. Since Bill and Margaret are splitting the Southwest, John needs to split divisional data in the company’s reports to measure this divisional structure. To do this, he creates two additional nodes within the hierarchy for the Southwest division, SWB (Southwest Bill) and SWM (Southwest Margaret).
Over time, Bill and Margaret move on to other jobs, either moving up in the company or on to other opportunities. Yet the Southwest division continues to be split into SWM and SWB. This is not an isolated occurrence, as many managers make isolated changes to the hierarchy structure. Some of these changes may not be warranted, and others may have a short shelf life. Soon the initial hierarchy is unrecognizable and difficult to manage. The ability to provide managers with rigid derived hierarchies, malleable explicit hierarchies, and focused collections allows BI professionals to provide the perfect tool for each scenario.
| Hierarchy Type | Description |
|---|---|
| Derived | Uses multiple entities. Based on domain-based attribute relationships. Level based. Hierarchy structure is designed in System Administration. Hierarchy members are updated in Explorer. |
| Explicit | Uses one entity only. Consolidated members are used to group other consolidated and leaf members. Ragged. Entity must be enabled for explicit hierarchies in System Administration. Hierarchy structure is designed in Explorer. Hierarchy members are maintained and updated in Explorer. |
Chapter 6: Using Business Rules
Managing data is not just about storing the data in a customized entity; it is also about ensuring that the data is both accurate and complete. Master Data Services provides business rules to achieve this aim. In this chapter, we review business rules.
Business Rules Overview
In many organizations, no matter what the size, the business owners responsible for managing the master data don’t have the technical knowledge needed to implement the related processes. If the business owners don’t know how to use SQL Server or how to code business rule engines, they can be left at the mercy of their IT departments. At the same time, because the IT department has the technical know-how, the burden often falls on them to learn business domains they don’t necessarily need to know. MDS strives to simplify the creation of business rules to empower business users to manage their own data quality.
In MDS, business rules are declarative expressions that govern the conduct of business processes. These expressions are compiled into stored procedures that perform the task of validating the data. The area of the Master Data Manager web application used for business rules was created to empower business users to write relatively complex business rules without knowledge of Transact-SQL.
Business Rule Structure
Business rules are IF…THEN statements. IF certain conditions evaluate to be true, THEN perform specific actions. Conditions can be combined using either AND or OR logical operators. These operators can be used to create extremely complex business rules. You can use as many as seven levels for complex conditioning.
Although you can create complex rules, there are some real benefits in creating multiple, more granular rules. You should consider breaking any rule that uses the logical OR operator in multiple rules. This makes rules easier for other users to read and understand. Multiple rules also allow you to exclude specific rules and to provide more granular notifications. Rules built with the AND operator must be kept together to function as a unit.
Business rules are always applied to attribute values. For example, if an attribute value is blank, you might want to send an e-mail to notify someone or set the value to Pending. Or you might want to update the value of one attribute based on the value of another attribute. Because business rules are applied to attribute values, you should determine which attributes you’re going to work with before you start creating rules. Each time you create a rule, you must select the model, entity, and type of member that contains the attribute you’re looking for.
Chapter 7: Creating Versions of Data
After you understand the workflow for adding and modifying the data stored in MDS, you must learn how to manage that data over time. For each model within MDS, a historical record of the data can be stored. These data snapshots are called versions.
Each time you create a version of a model, the data for all the entities within the individual model are versioned at the same time. Only the data is stored; any changes to the structure of the model affect all versions and can create unintended consequences.
Version flags are another important component of versioning in MDS. By assigning flags to versions, integration with other systems can be better managed.
There were no significant changes to versioning in the SQL Server 2012 release. Administrators should continue to use versions to manage snapshots of their models over time.
Versions Overview
To manage data within your organization effectively, you may be required to create versions of the data stored within a model. In MDS, the data in all entities within each model is versioned simultaneously. A benefit of this design is that you can manage relationships between entities without worrying about time and version. A side effect of this design is that entities in different models cannot interact with one another.
There is often a natural cadence to many data domains. This cadence can help define which entities should be managed in the same model. For example, in many organizations, the accounting department manages structural changes monthly. As each month ends, everyone in the accounting department goes through standard routines to ensure that the month’s books can be closed properly. Any entities related to this process—accounts, divisions, departments, or other internal business entities that are central to this process—should be managed together, and versioned in concert with the month-end process.
In another example, an organization may release products quarterly. All entities central to the product development process would follow this quarterly versioning scheme. Other entities may not require a versioning scheme at all.
Versions provide several benefits to the data management process:
- Complete model history for a specific point in time: MDS model versions can be committed to ensuring that an exact record of a model’s data can be stored for later review. These committed versions can provide a portion of the required audit trail for new, more rigorous compliance requirements.
- Limited access during sensitive processes: When performing certain processes, like validating the entire model or loading large numbers of records, it may be prudent to restrict access to the model by locking it.
- Additional version copies for analysis: Additional versions can be created outside of the standard cadence for a variety of purposes. These versions can be used to examine new hierarchy configurations or potential acquisitions without affecting the current regular processes.
Changing the Structure of Your Model
MDS does not version metadata changes. Any changes to the model structure affect all open and committed versions. If an attribute or entity is deleted, for example, all history for that attribute or entity is lost from all versions forever. When you need to maintain historic data, we suggest that you use security permissions to hide attributes or entities instead of deleting them. You can also hide attributes by setting the display width to zero or by not adding them to attribute groups.
When you add an attribute or entity, the model structure is updated in all versions as well. You can add the corresponding data to any version of the model; if you add data to a later version, the structure exists in the earlier versions, but the data does not.
Committing Versions
Sometimes users and downstream systems need to be certain that all data has been validated and reviewed. Because MDS allows incomplete members to be added to the system and encourages users to manage the data creation and correction workflow from within MDS entities, it may not be reliable for external production systems to use open or locked versions. Only committed versions ensure that all members in every entity within the model have passed all business rules successfully. Once a version is committed, no additional changes can be made to the data, and the status of the version cannot be changed.

Chapter 8: SQL Server 2012 MDS Add-In for Excel
More master data is stored in Excel than in any other application on the planet. Some smaller companies use this solution because it is cost effective and easy to use. Others use it to store their “homeless” data in worksheets because it is the tool they are most comfortable with. Even the largest organizations with the greatest, most well-designed MDM systems available struggle with the propagation of master data in Excel.
In SQL Server 2012, the Master Data Services team has attempted to harness the power of Excel to give users all the security, audit, and management features of MDS in a package that Information Workers are most comfortable with. In this chapter we will explore working with MDS data in Excel and the benefits of doing so.
Using the combination of Excel and MDS as a data management tool can provide organizations with significant advantages. Excel is a natural platform for staging data from a variety of sources. Its built-in data functionality can be used to parse and cleanse data before loading the data into MDS. The developer interfaces, whether code, macros, or formulas, can provide additional custom automation in a rapid fashion, without voiding any support in the MDS solution.
Many of Excel’s limitations are also addressed by using it in conjunction with Master Data Services. Data sharing, security, and transaction logging have always posed problems that spreadsheet designers have struggled to solve. One of the biggest concerns with storing data in Excel is the lack of security and central management. Using the MDS Add-In for Excel can alleviate many of these concerns.
Working with MDS Data in Excel
The Master Data Service Add-In for Excel will allow you to load entity data into a worksheet as an Excel formatted table. An Excel table is really a perfect environment to review and manage reasonable amounts of data from Master Data Services. Filtering, sorting, and formula functions can be used to review the data in a friendly format without destroying the ability to write back to the server. Data can also be taken “‘offline”’ and modified without connectivity and then published back to MDS when connectivity has been restored.
Summary
The MDS Add-in for Excel really changes the game in MDM, providing a well-known and efficient interface for all members of the enterprise to load and manage their data. The intuitive interface can create new entities, thereby eliminating or reducing costly modeling phases of MDM projects. In Chapter 11, the new modeling process will be discussed in greater detail.
Chapter 9: Implementing Security
By the time you are ready to implement security, most of the functionality in MDS has been enabled. Models have been built and refined, rules have been written, and the application has been integrated into your organization.
To deploy MDS, everyone needs access to the application. While transaction management can provide some accountability, limiting access based on needs and roles ensures that users are unable to change data without authorization. Limiting the number of models and functions available to users can also help them focus more quickly on the data they need. The ability to provide specific data access within the MDS system is the single most important feature of the application. The focused security access provided by MDS empowers business users and frees the IT organization to manage the overall process, not maintain the individual data points.
In this chapter we provide an overview of the security framework in Master Data Services. We discuss the process of managing user and group permissions and explain the highly customized access that can be granted.
Security Overview
MDS security is broken into three distinct areas:
- Functional security: Corresponds to each of the five functional areas displayed on the homepage of the Master Data Manager web application. Most users need access only to the Explorer functional area of the web UI. All other functional areas are available only to administrators. Users must have permissions to the Explorer functional area to use the MDS Add-in for Microsoft Excel.
- Model object security: Provides access control to attributes, based on the model objects within the MDS architecture. For example, you can set permissions on an entity, which determines permissions for all attributes for the entity. Or you can set permissions on a single attribute, which affects that attribute only. Model object security is required; without it, a user cannot perform any tasks in MDS.
- Hierarchy member security: Provides the most granular level of security and is optional. It is used to grant access to specific members, based on their location in a hierarchy.
Model object permissions (which apply to attributes) and hierarchy member permissions (which apply to members) are combined to determine the exact level of security for every attribute value. Figure 11-1 shows how attribute and member permissions intersect so that security can be determined for an individual attribute value.
- Hierarchy member permissions determine which members a user can read or update.
- Model object permissions determine which attributes a user can read or update.
Security Changes in SQL Server 2012
Security in the prior release of MDS was a double-edged sword. The ability to set security on multiple hierarchies simultaneously provided significant flexibility and complexity. But with so many pieces working together, it was easy for administrators to lose sight of what the effective permissions were for each user. A key effort for the second release of Master Data Services was to simplify the security model. In SQL Server 2012, Attribute Groups are no longer securable; you must set attribute security explicitly on each attribute. Direct hierarchy security has been removed from the security model.
Users and Groups
MDS relies on Active Directory for user and group authentication. While all security permissions are stored in the MDS database, no passwords or group memberships are managed in MDS.
To keep security as simple as possible, you should do the following:
- Create either Active Directory or local groups and add either Active Directory or local users to those groups.
- Assign security in MDS to these groups, rather than to individual users.
- If you decide to assign security to a user, don’t also assign security to groups that the user is a member of. While MDS has rules for determining which permissions take effect, security becomes more complicated when you do this.
Before you begin working with security, you should take some time to determine which groups your users might be part of, and which attributes or members those groups might need access to. The following list should give you a general idea of the groups that you might use.
- Product Administrators: This group will have permission to all functional areas and to take any action available for the Product model. This includes changing the model structure and modifying all members, among many other things.
- Finance Administrators: This group will have the same type of permission as the Product Administrators, but for the Finance model.
- Purchasing: This group will be able to update the Cost attribute for all products.
- Warehouse: This group will be able to update the attributes on the Logistics tab only.
- Logistics: This group will be able to update the Safety Stock Level, Reorder Point, and Discontinued attributes. All other attributes will be read-only.
All these groups will be able to access MDS after being assigned functional area and model object permissions. You might also assign hierarchy member permissions to a few select members of the Purchasing group. These users should be able to view products for only the manufacturers they are responsible for.
Even though we recommend that you assign permissions to groups, for the rest of this chapter we’ll refer to permissions that users receive, because groups wouldn’t mean anything if users weren’t in them. They are ultimately the ones who will access the data.
Administrators
In MDS there are two types of administrators:
- The system administrator you specified in the Administrator Account field when creating the MDS database. This user has full control over all models and data. When new models are created, this user automatically has access. This user also has permission to access all functional areas of the web UI. To change this user, you must run a stored procedure in the database.
- A model administrator who is manually assigned Update permission to a model, and no other model object or hierarchy member permissions. This user has full control over the model he or she has Update permission to. Model administrators do not necessarily have permission to access all functional areas of the application. For example, a model administrator might be responsible for integration only. However, they can perform all tasks in whichever functional area they have permission to access. All model administrators with access to the User and Group Permissions functional area can assign permissions for other users. Keep this in mind when you’re assigning someone permission to update a model.
Functional Area Permissions
Functional area security determines which of the five functional areas on the Master Data Manager home page a user or group can access. Security at this level is either permitted or denied. If permission to access a specific functional area is denied, the area is not displayed in the web UI and related web service operations are denied.
The Explorer functional area is where users manage data. When you assign access to Explorer, you must assign access to specific model objects, so the user gets access to a specific set of data. When you assign access to any of the other functional areas, the user must have access to the entire model (on the Models tab) in order to use those areas. Without this access, the user can open the functional areas, but no models are displayed. This is how MDS handles permission for Administrators.
Model Object Permissions
Model object permissions, assigned on the Models tab, are required. Users cannot view any models or data if they do not have model object permissions.
When you give users permission to model objects, you are giving them the ability to edit attributes for members, based on the object you select. For example, if you set Update permission on the Product entity, all attributes for all Product members (leaf and consolidated) can be updated. If you set Update on the Color attribute of the Product entity, only the Color attribute can be updated.
In addition to giving a user the ability to update attribute values, if you assign Update model object permissions to a model, entity, or to the word “Leaf” or “Consolidated,” the user can also create and delete members. If permissions are assigned at a lower level, the user cannot create and delete members.
Note: Permissions automatically cascade to all child objects within the current model unless permissions are assigned at a lower level. You do not need to explicitly set permission on every object.
If you assign Update model object permissions to the model only, the user is an administrator, which means he or she can access the model in functional areas other than just Explorer if given to access to that functional area.
Quick Facts About Model Object Permissions
Things to remember about model object permissions include the following:
- They are required.
- They determine which attributes a user can view or update (as opposed to which members).
- They apply to all lower-level objects unless another permission is explicitly assigned.
- Update permission to Leaf or Consolidated model objects and above gives users the ability to create and delete members.
- Update permission at just the model level makes the user an administrator.
Best Practice for Model Object Permissions
There are many different model objects you can assign permission to. Giving access to specific models, entities, or attributes should fulfill most of your security needs. In SQL Server 2012, most complicated security configurations have been simplified with the removal of attribute group and hierarchy object security.
Chapter 10: Publishing Data to External Systems
Although the ability to manage data is an important feature of Master Data Services, the ability to export data to other systems in the enterprise is equally if not more important. MDS has simplified the export process by providing subscription views that you can create on any entity or derived hierarchy object within the MDS system.
In this chapter, we describe the different types of the export views that can be created and the format of each of these views. While Master Data Services provides no direct Extract, Transform, and Load (ETL) features of any kind, the Integration Management functional area of the Master Data Manager web application (or “web UI”) can facilitate your integration processes by providing a wide variety of views to assist in the loading of downstream systems.
Exporting Data to Subscribing Systems
Master Data Services can provide value for a project that keeps the data locked in its entities by providing processes around the data management; however, to meet the operational or analytical needs of a master data management project, organizations need to transport stored data downstream to subscribing systems. To insulate organizations from the complex object model necessary to manage performance and the customization necessary within MDS, the developers created a subscription view layer.
You can create subscription views within the Integration Management functional area of the web UI, or by using the web service. The web service refers to these views as export views, but we’ll use “subscription views” and “export views” interchangeably.
Subscription View Formats
The following table shows the available subscription view formats. When you create a subscription view, you must choose which format you want to use. There are two major types of subscription views within MDS: attribute views and hierarchy views. Attribute views display the data stored for leaf, consolidated, or collection members in an easily consumable tabular view. Hierarchy views provide relationship data for all types of relationships in MDS, whether explicit or derived hierarchies or collection members. Collection member relationships can only be displayed in a parent-child format. An additional view is available for derived and explicit hierarchies. It contains a row for each member and the parentage all the way to the top consolidation in the hierarchy; this view is considered level-based.
| View Format | Description of View |
| Leaf attributes | Shows leaf members and their associated attribute values |
| Consolidated attributes | Shows consolidated members and their associated attribute values |
| Collection attributes | Shows collection members and their associated attribute values |
| Collections | Shows collections and their members in a parent-child format |
| Explicit parent child | Shows explicit hierarchy structures for an entity in a parent-child format |
| Explicit levels | For the entity, shows all members in all explicit hierarchies in a level-based format |
| Derived parent child | Shows all derived hierarchy members in a parent-child format |
| Derived levels | Shows all derived hierarchy members in a level-based format |
Common View Architecture
Many of the columns in Master Data Services’ subscription views are identical across view types. The columns provide either context for the data displayed in the view or additional system information for the records contained in the view. Subscribing systems can use this information to update a subset of records based on validation status or last updated statistics.
| Column | Description |
| VersionName | The version name for the current version being displayed. If this is a view based on the version name, this value will never change. |
| VersionNumber | The version number for the current version being displayed. If this is a view built on the version name, this value will never change. |
| VersionFlag | The current version flag for the displayed version. If a view is based on a version flag, then this column will remain constant and the VersionName and VersionNumber column values will change as the version flag is moved between versions. |
| EnterDateTime | The date and time the member was first entered into MDS. |
| EnterUserName | The user who initially entered the member into MDS. |
| EnterVersionNumber | The initial version this member was created in. |
| LastChgUserName | The user who last updated this member in MDS. |
| LastChgVersionNumber | The number of the version this member was last changed in. |
| ValidationStatus | The current validation status for the member. Validation status only exists for leaf, consolidated, and collection attribute views, because there is no validation stored for relationship members. |
Chapter 11: Advanced Modeling
Modeling is more art than science. You must understand not only your datasets and how they interact, but you also need to understand the related systems, people and processes.
Master Data Services is not a data warehouse or a reporting tool. It is a data management tool. This is a difficult distinction for many to understand. Master Data Services should be used to manage and store lists for the business. Security can create boundaries for multiple users. Business rules notify users of issues with the data, while the Web UI, Add-In for Excel, and Web Service give the entire organization access to work on the same datasets. All these features are designed around managing data changes.
Once data is being managed correctly in MDS, ETL processes can send this data into data marts and warehouses to provide the reports demanded by the business. These systems can focus on the reporting structures, disseminating the information without concern for the data editing and quality processes. In this chapter, we will try to provide insight into some of the more common complex problems that we have seen.
Common Modeling Mistakes
MDS is best built from the top down, not the bottom up. As we discussed in Chapter 3, the first step in managing data is to determine the major entities that need to be managed. Unfortunately, many modelers then move directly to the downstream systems to build their models, deriving all columns from these pre-existing systems. This section discusses some significant pitfalls with this approach to be aware of.
Building Outside Limitations into MDS
Whether a system is purchased or created, the data model of that system was developed through a series of compromises. If you were building a system to manage payroll, how many attributes would you add for each employee? Would you add information about certifications they hold? Each system is built to solve a business need. Some of these systems will attempt to solve multiple needs or allow for minimal customization. If you focus on a single system, you run the risk of bringing these compromises into MDS.
A couple of common compromises seen in the field are perpetuating overloaded fields into your MDM system and propagating system column names. Either of these issues can blunt the effectiveness of your MDS implementation, limiting usability for business users.
Manage Overloaded Fields
Many systems have tables that need to have a single column they use as the primary key. To ensure this column is always unique, values in this column may be a combination of three or more distinct values that have been pasted together, typically as a fixed-length combination. Do not bring this as a single column into MDS. Allow users to manage these distinct values separately. If visibility of this value is required, use business rules to concatenate the obscure codes into this overloaded value for the external systems.
Provide Easily Recognizable Names
Most systems try to use standard naming conventions and technical shorthand to name tables and fields within the database. Ensure that you adapt these names to be easily readable by your end users. This might apply to allowable values within some fields as well. Create an entity and provide useful names to each of these unique values.
Trouble Identifying Common Attributes
Each system within your enterprise comes pre-configured with some built-in nomenclature and culture. If you look at these systems at the database level, where table and column names have been abbreviated, determining meaning and use can be difficult. This can lead to confusion about how different systems or departments manage similar attributes. While these architecture diagrams can help lead the conversation, working directly with the business users is the best way to ensure you accurately model your business.
Engineering Dead Scenarios
When we rely on the existing structures of systems within the organization, we may find ourselves modeling scenarios the business does not require. This can be due to changes in the business structure over time or an incomplete understanding of the problem when the system was implemented. It is important to take advantage of the current mindshare of the business users and to build your MDS model as the business intends.
Rapid Model Development
With the advent of the MDS Add-In for Excel, Master Data Services has revolutionized the modeling process. In the past, there was a gulf between modelers who read and create data models and the rest of the business. The best way to bridge this gulf is to design a model, review it with the users, receive feedback, and repeat the process. With competing products, this process usually takes weeks or months for each iteration, whereas with the Add-In for Excel, a team can create a fully populated model in a few days.
Excel is a great intermediate location for data from any source. Many of the datasets currently managed in your organization already exist within Excel. For any data that does not exist in an Excel sheet, you can use the existing data features in Excel to load the data into a workbook. Once the data is loaded into Excel, you can create a new entity by using the Create Entity Wizard.
Managing Slowly Changing Dimensions
One of the most common concerns when helping data stewards model data in MDS is how to handle history within the system. In most cases, these concerns are not drawn from operational systems, as these systems typically focus on the processing of the current state. Analytic systems such as data warehouses or data marts need to store or report information based on changes over time. Most modeling discussions quickly turn to managing these dimensions changes in MDS. This is the wrong way to look at it. The role of MDS is to create the changes, not to store them for reporting purposes. We need to look at how to leverage the existing tools in MDS to send these changes to the reporting systems that require them.
Conclusion: Superseding MDS with Master Data Management
Whether you have dabbled with SQL Server Master Data Service (MDS) for your master data needs or you’ve gone deep with a full production solution, there are reasons you should be concerned that your investment in MDS is at risk and that you may be limiting ourself unnecessarily.
MDS was a fine tool for building small–scale, departmental data management solutions. However, once you decide to get serious about master data management, you need real tools and a vendor to partner with, like Profisee, that brings to the table a forward-looking plan and migration strategy for moving beyond MDS.
Profisee offers a unique approach to MDM that helps organizations of all size make their data management easy, accurate and scalable.
Schedule a demo today to see first-hand how the Profisee MDM platform can solve your unique business challenges.

