























![Header image for Data Quality - What, Why, How, 10 Best Practices & More [2026]](https://profisee.com/wp-content/uploads/2023/08/Skyscraper-DataQuality_Social_1200x628.jpg.webp)
Data excellence relies on balancing two primary criteria:
- Fitness for use: The degree to which data is precise, complete, consistent and reliable for its intended purpose.
- Real-world representation: The degree to which data accurately describes the actual entity.
Effective data management establishes the reliability needed to use information across different systems and use cases. Poor data quality — including duplicates, missing values or inconsistent records — distorts insights and creates operational risk. Correcting these failures requires a coordinated mix of people, processes and technology driven by engaged leadership.
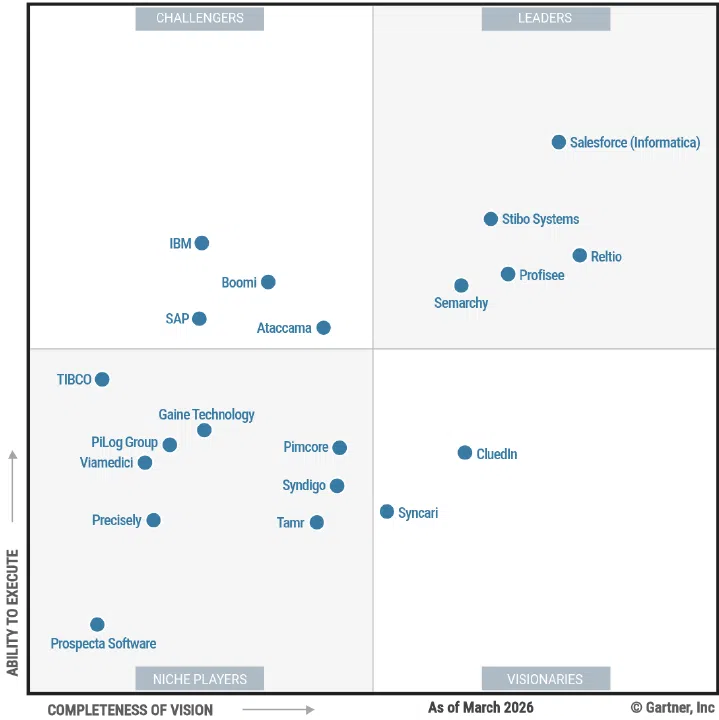
Discover how leading organizations improve data quality and prepare records for AI. Download The State of Master Data Management 2026 Report.

Top 11 Data Quality Best Practices
To maintain high-quality enterprise information, follow these 11 best practices.
- Secure executive sponsorship to unify departments: Most issues require a cross-departmental perspective that only top-level management can facilitate to ensure alignment across silos.
- Integrate quality initiative with data governance: Embed all activities within a formal framework that defines policies, standards, roles and a shared business glossary.
- Assign data quality accountability to business-led roles: Choose data owners and stewards from business teams and pick custodians from business or IT based on what’s needed technically.
- Leverage a business glossary for metadata: Use common definitions to link metadata across current and future applications, ensuring a unified language for all stakeholders.
- Ensure a comprehensive issue log: Document every problem with its assigned owner, business impact, resolution steps and expected timeline for remediation.
- Prioritize root cause analysis: Investigate the origin of every reported error; sustainable improvements only occur when the source of the problem is fixed.
- Shift focus to prevention: Implement processes and technology that stop errors at the point of onboarding rather than relying on expensive downstream cleansing.
- Align quality KPIs with business performance: Guarantee your health metrics — such as uniqueness, completeness and consistency — directly support overall organizational goals.
- Use data failure examples and financial risk assessments: Share train wreck examples to show what’s at stake, but use data-driven risk analysis to make the case for funding solutions.
- Automate onboarding with outside sources: Cut down on manual entry by using third-party data for locations and companies or data from partners for product records.
- Prioritize AI-ready data: Align data standards with specific AI model or business unit requirements to fulfill exact accuracy needs without unnecessary over-engineering.
Scale High-Quality, AI-Ready Data With Profisee
To put your data quality strategy into action, you need a platform built for the scale and speed of AI. Profisee connects scattered data and creates a reliable source of truth. We focus on truth in bounded contexts, helping your business stay competitive and prepared for new models.

Profisee MDM automates the most labor-intensive parts of data management, allowing you to maintain high-quality information with far less manual effort:
- Streamline data stewardship: Use the Aisey agent to manage records via natural language. Our agent works semi-autonomously to handle routine tasks like classification, verification and validation.
- Resolve complex duplicates: Build reliable golden records with machine-learning matching engines. These tools spot unusual patterns and manage complex record links much more accurately than traditional, rule-based methods.
- Integrate with your tech stack: Keep quality across your entire ecosystem with a native Microsoft Fabric workload and OpenAPI services designed for high-volume, modern environments.
Start managing data quality. Book your Profisee demo today.

