























- Data Architecture Definition
- Benefits and Costs of Creating a Data Architecture
- What Are the Types of Data Architecture?
- What Are Some Common Data Architecture Frameworks?
- Best Practices for Building a Data Architecture
- Building a Data Architecture Diagram
- Supporting Technologies of Data Architectures
- Complete Your Data Architecture with Master Data Management (MDM)
- Cloud-Native Master Data Management
- Cloud-Native Master Data Management
Data architecture is a crucial element in modern businesses, providing the blueprint for managing data assets effectively. As a function of desired data outcomes and the organization’s existing operating model, data architecture also has big implications for the organization’s data governance model and master data management (MDM) implementation style, so it’s important to get it right.
In this article, we’ll explore the ins and outs of data architecture, including its definition, frameworks, types, benefits, costs, best practices, diagram creation and the underlying technologies that support data architectures. Let’s get started!
Data Architecture Definition
Data architecture refers to the structured design of data systems, policies and standards that an organization uses to manage its data assets. It lays the foundation for data collection, storage, integration and utilization, aligning these processes with business goals and technical requirements.
By defining how data is processed, stored and accessed, a data architecture ensures consistency, quality and security of data across the enterprise and enables strategic initiatives like business intelligence or AI adoption.
If this still sounds abstract, that’s because data architectures are not a one-size-fits-all solution. Similar to the way organizations define data quality, data architectures arise from business needs. Depending on what a business wants to accomplish with its data, a data architect might decide to design the architecture several different ways.
Benefits and Costs of Creating a Data Architecture
For any large organization — and for those at the enterprise level, in particular — establishing data architecture is not an option, but a requirement. Without it, embarking on any kind of serious data initiative will be very difficult, if not impossible.
That being said, it’s still important to bear in mind the costs and benefits of establishing a data architecture. The idea here isn’t to help you decide whether or not to build one (again, you should) but to help you better anticipate potential challenges that may arise throughout the process and to help you gain buy-in from the many stakeholders needed to pull it off.
Benefits
| Pro | Improved data governance: It facilitates better data governance, ensuring compliance with regulations and protecting sensitive information |
| Pro | Scalability: Scalable data architectures allow organizations to handle growing data volumes efficiently |
| Pro | Data integration: It enables seamless data integration from disparate sources, providing a unified view of information |
| Pro | Informed decision-making: High-quality, well-managed data supports accurate and timely decision-making processes |
| Pro | Better customer experience and business processes: Properly managed data helps improve customer experiences through more seamless, personalized sales and support flows in addition to business processes like optimized procurement or better location management |
Costs
| Con | Financial investment: Implementing a robust data architecture requires significant financial resources for hardware, software and personnel |
| Con | Complexity and maintenance: Designing and maintaining a data architecture is complex and demands ongoing efforts from skilled professionals |
| Con | Change management: Adopting new data architectures may require changes in organizational culture and processes, which can be challenging and potentially disruptive to business processes |
What Are the Types of Data Architecture?
Data architectures can be classified into various types based on their structure and purpose. It’s important that the architecture supports the organization’s operating model (more on that in a bit) and not the other way around.
Whether your organization operates as centralized (data is managed from the top-down), federated (data is managed locally following commonly-defined rules) or decentralized (data is managed differently across the organization with no commonly-defined rules) or some hybrid of the three, choose the type of data architecture that best suits your organization’s operating model.
1. Data Warehousing Architecture
A data warehousing architecture involves designing systems for collecting, storing and analyzing large volumes of historical data in a relational database. It includes components like ETL (extract, transform, load), data marts, metadata, reference data and OLAP (online analytical processing).
A data warehouse architecture is typically further broken down into three different styles: single-tier, two-tier or three-tier architectures. A three-tier architecture might be the most popular style, as it employs ETL to load clean data into the data warehouse where data marts then make the data accessible to end users for functions like data analytics and data mining.
2. Data Lake Architecture
A data lake architecture is designed to store vast amounts of raw data in its native format until it’s needed. This architecture supports big data analytics, enabling organizations to process and analyze diverse data types on a large scale.
A data lake architecture is similar to a data warehouse architecture — and the former usually incorporates the latter into its design — in that it enables the storage of large amounts of data. However, the big difference between these two is that data lake architectures enable storing both structured and unstructured, relational and non-relational data.
A data engineer doesn’t necessarily need to cleanse data before it’s ingested into a data lake. Rather, data lakes assist in breaking down data silos and integrating data from disparate sources before it’s cleaned and loaded into a data warehouse.
3. Data Mesh Architecture
A data mesh architecture decentralizes data ownership by domain, promoting a federated governance model. This relatively new architectural pattern aims to improve scalability, flexibility and accessibility across different business units.
Unlike a more traditional approach — like having one dedicated team who manages data in a data warehouse architecture — data meshes grant individual teams more autonomy and responsibility over the data they need for analytics and other functions.
This eliminates bottlenecks that tend to arise under more centralized architectures, especially with the ever-increasing number of data sources stemming from broader software engineering trends like microservices architectures.
4. Data Fabric Architecture
A data fabric architecture creates a unified data management environment, integrating data across various sources and platforms. It focuses on providing consistent data services, improving data accessibility and reducing silos.
This architectural pattern is nascent. It’s young, and data professionals are still working to figure it out. However, platforms like Microsoft Fabric and its OneLake architecture are working toward bringing a true data fabric to maturity.
One of the biggest benefits of data fabrics apart from creating an integrated layer of connected data is that they incorporate existing investments into data warehouses and data lakes. Instead of majorly disrupting the existing data architecture, a data fabric builds on to or augments the architecture currently in place to improve data integration and delivery.
What Are Some Common Data Architecture Frameworks?
Data architecture frameworks provide a structured approach to designing and implementing data systems. Data architects don’t need or want to reinvent the wheel when it comes to designing an organization’s data architecture — frameworks provide a series of best practices to keep them from doing so.
Familiarize yourself with the two most common frameworks to get a sense of what approach your organization should take.
The Data Management Body of Knowledge (DAMA-DMBOK)
The DAMA-DMBOK framework offers guidelines and best practices for data management, covering data governance, quality, architecture, modeling, storage and security. It’s widely used for developing and managing data architecture in organizations and, in many ways, sets the industry standard for many data management principles more generally.
If you’re looking for a good resource on data architecture, consult the DMBOK. Data architecture is a central part of this framework, so it’s a helpful reference source to have on hand.

The Open Group Architecture Framework (TOGAF)
TOGAF is a comprehensive framework that guides the development of enterprise architecture, including data architecture. It provides tools and methodologies for designing, planning, implementing and governing enterprise data architectures, based on information sharing through The Open Group Architecture Forum, a collaborative group consisting of organizations from around the world, including Huawei, IBM, Shell and Intel.
Best Practices for Building a Data Architecture
1. Define Clear Objectives
Before designing a data architecture, establish clear objectives aligned with business goals. Understand the specific needs of your organization and the problems you aim to solve with data architecture.
2. Adopt a Scalable Design
Ensure that your data architecture is scalable, accommodating future growth in data volume and complexity. Use modular designs to facilitate easy expansion and upgrades.
3. Prioritize Data Quality
Implement robust data quality management practices, including data cleansing, validation, de-duplication and monitoring. High data quality promotes reliability and accuracy in decision-making.
4. Implement Strong Data Governance
Establish comprehensive data governance policies, covering data ownership, stewardship and compliance. Effective governance promotes accountability and consistency across the organization.
5. Leverage Automation
Utilize automation tools for data integration, processing and management to reduce manual efforts and minimize errors. Automation enhances efficiency and consistency.
6. Invest in Security
Implement stringent data security measures to protect sensitive information from unauthorized access and breaches. Use encryption, access controls and regular audits to ensure data protection.
7. Foster Collaboration
Promote collaboration between data professionals, business stakeholders and IT teams. Collaborative efforts ensure that data architecture meets diverse needs and drives organizational success.

Building a Data Architecture Diagram
Creating a data architecture diagram is a critical step in visualizing and communicating your data architecture. Here’s how to build an effective diagram:
1. Identify Key Components
List the essential components of your data architecture, including data sources, storage systems, processing tools and data consumers.
2. Define Relationships
Map the relationships between different components in an architectural diagram, illustrating how data flows through the architecture. Use arrows and connectors to show data movement and integration points.
3. Use Standard Symbols
Adopt standard symbols and notations for representing different elements, ensuring clarity and consistency. Common symbols include databases (cylinders), processes (rectangles) and data flows (arrows).
4. Add Annotations
Include annotations to explain the purpose and functionality of various components. Annotations provide context and help stakeholders understand the architecture.
5. Keep it Simple
Avoid overloading the diagram with excessive details. Focus on the core components and their interactions, keeping the diagram clear and easy to interpret.
6. Regularly Update
As your data architecture evolves, update the diagram to reflect changes. Regular updates ensure that the diagram remains accurate and useful.
Supporting Technologies of Data Architectures
Modern data architectures rely on a variety of technologies to manage, process and analyze data. The architectural pattern you decide to use will most likely incorporate all or some of the technologies below.
1. Databases
Relational databases (e.g., MySQL, PostgreSQL) and NoSQL databases (e.g., MongoDB, Cassandra) are fundamental for storing structured and unstructured data. Some popular database solutions include Azure SQL and Amazon Relational Database Service (RDS).
2. Data Integration Tools
ETL tools (e.g., Azure Data Factory, Databricks Data Intelligence Platform) and data integration platforms (e.g., Apache Nifi, MuleSoft) facilitate data extraction, transformation and loading across systems.
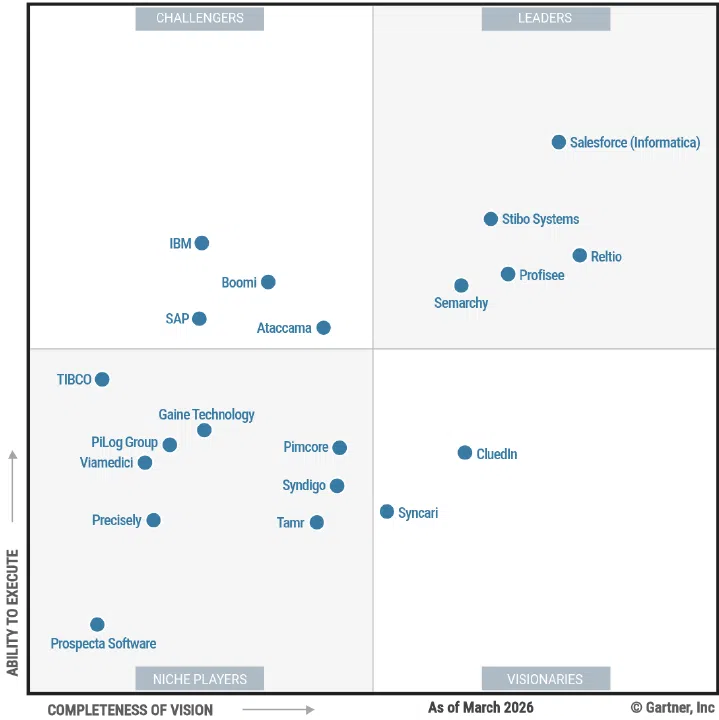
3. Master Data Management (MDM) Tools
Master data management tools like Profisee are essential for getting the most out of an organization’s data and are key enablers of data fabric architectures. MDM lets you integrate master data from multiple disconnected systems and match, merge and standardize it to create a single source of truth of usable data for other systems, like business intelligence, customer relationship management and data warehouse tools.
4. Customer Relationship Management (CRM) Systems
CRM solutions (e.g., Salesforce Sales Cloud, HubSpot Sales Hub) let businesses store valuable information about their customers, leads, opportunities and closed deals. CRMs store large amounts of data about customers and how the revenue organization interacts with them. They are typically integrated with other systems like marketing automation and analytics.
5. Enterprise Resource Planning (ERP) Systems
ERP systems (e.g., SAP S/4HANA, Oracle NetSuite, Odoo ERP) are expansive software systems used across the enterprise. Usually divided into modules, ERP systems handle functions like accounting and finance, inventory management, supply chain management, order fulfillment, human resource management and more.
6. Big Data Platforms
Big data platforms (e.g., Apache Hadoop, Apache Spark) enable the processing and analysis of large-scale datasets, supporting advanced analytics and machine learning.
7. Data Warehousing Solutions
Data warehousing solutions (e.g., Amazon Redshift, Google BigQuery) provide architectures for storing and querying large volumes of structured data efficiently.
8. Data Lake Solutions
Data lake solutions (e.g., Amazon S3, Azure Data Lake) offer scalable storage for raw data, supporting diverse data types and advanced analytics.
9. Data Visualization Tools
Data visualization tools (e.g., Tableau, Power BI) enable users to create interactive visualizations and dashboards, facilitating data-driven insights and decision-making.
10. Data Governance Platforms
Data governance platforms (e.g., Microsoft Purview, Alation Data Intelligence Platform) help manage data policies, data catalogs and compliance, ensuring data quality and accountability.
11. Cloud Services
Cloud services (e.g., AWS, Google Cloud, Microsoft Azure) provide scalable, flexible infrastructure for hosting data architectures, supporting storage, processing and analytics.
Complete Your Data Architecture with Master Data Management (MDM)
Data architecture is a vital component of modern data management, offering a structured approach to handling data assets effectively. By understanding the different types of data architectures, leveraging best practices and utilizing the right technologies, organizations can build robust data systems that drive innovation and growth.
Are you ready to transform your data management strategy? Learn more about the role master data management plays in data architectures and how you can implement it regardless of data architecture or cloud provider.
Cloud-Native Master Data Management
Cloud-Native Master Data Management

Benjamin Bourgeois
Ben Bourgeois is the Head of Product and Customer Marketing at Profisee, where he leads the strategy for market positioning, messaging and go-to-market execution. He oversees a team of senior product marketing leaders responsible for competitive intelligence, analyst relations, sales enablement and product launches. He has experience managing teams across the B2B SaaS, healthcare, global energy and manufacturing industries.

